大家好,我是小眼睛优粥面,上一篇文章和大家简单聊了一聊python垃圾回收中的 “标记清除” 和 “分代回收” 机制,我们用几句话简单总结一下前面我们介绍的内容。
在python内部中自己维护了一个refchain双向环状链表,我们使用程序创造的所有对象都会存到这个链表中,而每一个对象都记录着一个引用计数器的值(ob_refcnt),对象被引用时引用计数器+1,删除引用时引用计数器-1,最后当引用计数器的值变为0的时候,则启动垃圾回收机制,即从双向链表中将该对象删除。但是在python中对于那些有多个元素组成的对象存在循环引用的问题,为了解决这个问题python又引用了标记清除和分代回收机制。但是如果就这样完事了,那岂不是太简单,python源码内部在上述的流程中还做了一些优化,那就是:缓存机制。今天我们就来聊一聊这块的内容。
欢迎大家交流分享(码字不易,希望大家标明出处),有不对的地方请大家指正,也希望大家关注我的微信公众号 “记不住先生和忘不了小姐”,里面不光有 “记不住” 的技术还有那 “忘不了” 的情怀,万分感谢啦^ ^
Python中缓存机制主要分为两大类,分别是 “缓存机制” 和 “free_list机制”,缓存机制有可细分为:小数据池和驻留机制,我们详细来看一下。
所谓小数据池,就是为了避免重复创造和销毁一些常见对象,python在其内部会自己维护一个缓存资源的操作,我们看这么一个代码(python版本3.7.6)。
Python 3.7.6 (tags/v3.7.6:43364a7ae0, Dec 19 2019, 00:42:30) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> p1 = 1 >>> p2 = 1 >>> print(id(p1)) 140734330597648 >>> print(id(p2)) 140734330597648 >>> p3 = 257 >>> p4 = 257 >>> print(id(p3)) 559876634128 >>> print(id(p4)) 559876633520我们都知道,正常情况下,如果我们运行python程序的时候是先会先向内存去申请一块内存空间,用来存储我们的数据。每次变量的赋值理论上都会开辟新的内存空间,而程序在内存中存储数据是按照空间连续去存储的,所以按道理变量p1和变量p2应该指向不同的内存地址,但我们这上面为什么是同一个呢。
这是因为python为了节省资源,避免重复创建和销毁一些常见的对象,它在启动解释器的时候自动创建了一些默认的 “缓存池”,对于部分小整型和字符型执行缓存机制。即将这些对象进行预先创建,不会为相同的对象分配多个内存空间,这些数据包括:
在解释器启动的时候,python会自动创建以下小数据池,如果是不同代码块中的两个变量,并在此范围内,那么它们具有相同的id值,即重复使用这个范围的内容时,不会重新开辟内存空间,具体内容如下:
(1)small_ints链表:存储 -5,-4,-3,...,256 范围内(-5 <= value < 257)的整数。
(2)unicode_latin1[256]链表:存储所有的 ascii 字符,以后使用时就不再反复创建。
(3)布尔型满足小数据池
注意这块提到的一个注意事项(坑),那就是 “不同代码块中的” ,那么什么是不同的代码块呢,这块很重要。
2. 代码块
我们继续讲剩下的缓存机制之前,插入一下这个概念。我们先看一下官方的解释。
A Python program is constructed from code blocks. A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition. Each command typed interactively is a block. A script file (a file given as standard input to the interpreter or specified as a command line argument to the interpreter) is a code block. A script command (a command specified on the interpreter command line with the ‘-c‘ option) is a code block. The string argument passed to the built-in functions eval() and exec() is a code block.
A code block is executed in an execution frame. A frame contains some administrative information (used for debugging) and determines where and how execution continues after the code block’s execution has completed.
以上是对于代码块 python 官方文档的解释。也就是说,Python 程序是由代码块构造的,其中块是一个 python 程序的文本,作为一个程序执行的的基本单元。
代码块主要含义:“一个模块,一个函数,一个类,一个文件” 中的代码都属于同一个代码块。而作为交互式方式(命令行进入解释器操作)输入的每个命令都是一个代码块。这也就很好的解释了为什么我们在 “交互式命令行” 、 “xxx.py文件” 、 “pycharm中” 中运行以上同样的代码结果不一致的问题(图一p3和p4内存地址不一致,图二p3和p4内存地址一致),如下图所示:
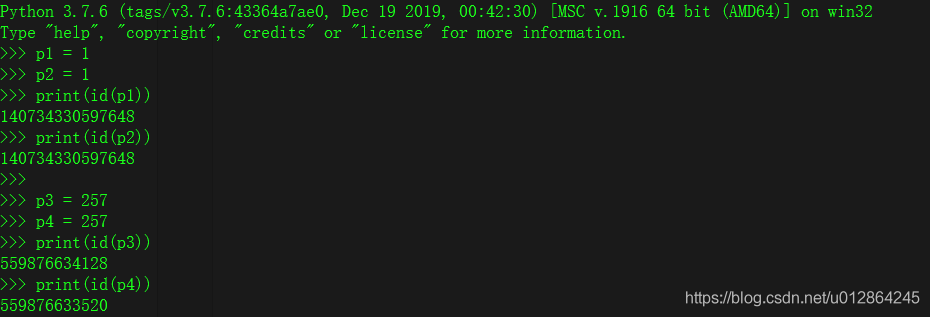
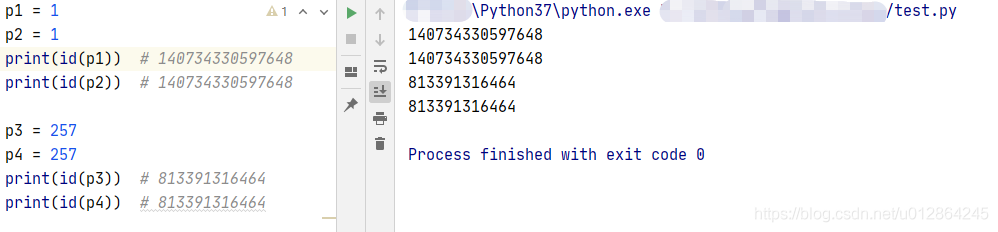
因为通过命令行进入Python解释器里面,每一行代码都是一个代码块,而在pycharm下一个文件下就是一个代码块。但是对于一个文件中的两个函数,分别是两个不同的代码块,比如这样:
def func01(): p1=257 print(id(p1)) def func02(): p2=257 print(id(p2)) # 其中,func01和func02为两个代码块 func01() # 574636218224 func02() # 574637180400python的驻留机制是python系统内部维护了一个叫 “interned” 的字典,当允许被驻留的数据首次创建时,会被记录到该字典中,如果在 “同一个代码块中(注意)” 该数据被删除或者被其他对象再次引用时,不开辟新的内存空间,而是直接指向驻留空间中的内存地址,这样可以大量的节省内存空间。
注意一点的是:本人发现这个机制在python的不同版本中还不一致,在 python3.x 中的某些版本中该内容做出了调整,但在 python2.x 中仍保留了该部分,所以说大家可能看一些其他人的博客介绍驻留或缓存机制的时候,有一些代码在python3中运行结果跟他们写的不一致,这问题也困扰了许久,导致这篇博客推迟了很久才发出来,本文我们会对对我们的想法进行验证,同时后期会找寻一些官方的资料进行佐证。首先,我们具体看一下哪些数据在python2.x中会被驻留(这里使用python版本为2.7.6)。
(1)整型、浮点型,所有整型和浮点型在目前python的所有版本中均满足驻留机制
# 所有整型均满足驻留机制 a = 8888888888888888888888888888 b = 8888888888888888888888888888 print(id(a)) # 44311456 print(id(b)) # 44311456 print(a is b) # True # 所有浮点型均满足驻留机制 a = -0.568888888888888888888888888888 b = -0.568888888888888888888888888888 print(id(a)) # 39583696 print(id(b)) # 39583696 print(a is b) # True(2)布尔型,在 Python2 中是没有布尔型的,它用数字 0表示 False,用 1 表示 True。到 Python3.x 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0。但无论是2.x还是3.x均满足驻留机制。
# 布尔型满足驻留机制 a = True b = True print(id(a)) # 505513920 print(id(b)) # 505513920 print(a is b) # True(3)字符型,字符串的驻留机制比较复杂,而且对于python不同版本还有所不同,我们拿python2.7.5和python3.7.4做一个比较。
- 单一字符串,满足驻留机制
# 单一字符串,在python2.7.5和3.7.4版本均满足驻留机制 a = "This_is_string_111111111111111111111" b = "This_is_string_111111111111111111111" print(id(a)) # 44245856 print(id(b)) # 44245856 print(a is b) # True- 乘法得到的字符串,在python2.7.5中,运行结果如下:
# -*- coding: utf-8 -*- # 非乘法得到的字符串,都满足代码块驻留机制 a = "这是一个非乘法等到的字符串,都满足代码块驻留机制!" b = "这是一个非乘法等到的字符串,都满足代码块驻留机制!" print(id(a)) # 41011888 print(id(b)) # 41011888 print(a is b) # True # 乘数为1时,任何字符串都满足代码块驻留机制 a = "乘数为1时,任何字符串满足代码块的驻留机制。" * 1 b = "乘数为1时,任何字符串满足代码块的驻留机制。" * 1 print(id(a)) # 48850176 print(id(b)) # 48850176 print(a is b) # True # 乘数>=2时:仅含大小写字母,数字,下划线,且总长度<=20,满足代码块驻留机制 a = "ab_32" * 4 b = "ab_32" * 4 print(id(a)) # 41927040 print(id(b)) # 41927040 print(a is b) # True c = "ab_32" * 5 d = "ab_32" * 5 print(id(c)) # 51417392 print(id(d)) # 51987120 print(c is d) # False- 而以上代码在 python3.7.4 中运行却得到了不同的结果:
# 非乘法得到的字符串,都满足代码块驻留机制 a = "这是一个非乘法等到的字符串,都满足代码块缓存机制!" b = "这是一个非乘法等到的字符串,都满足代码块缓存机制!" print(id(a)) # 1867641922480 print(id(b)) # 1867641922480 print(a is b) # True # 乘数为1时,任何字符串都满足代码块驻留机制 a = "乘数为1时,任何字符串满足代码块的缓存机制。" * 1 b = "乘数为1时,任何字符串满足代码块的缓存机制。" * 1 print(id(a)) # 1867642068016 print(id(b)) # 1867642068016 print(a is b) # True # 乘数>=2时:任何字符串都满足代码块驻留机制 a = "ab_32" * 4 b = "ab_32" * 4 print(id(a)) # 1867639964816 print(id(b)) # 1867639964816 print(a is b) # True c = "ab_32" * 5 d = "ab_32" * 5 print(id(c)) # 1867642328448 print(id(d)) # 1867642328448 print(c is d) # True我们可以看到在python3.7.4中,所有的字符串均保留了驻留机制。
在我们之前介绍的内容中,当我们引用计数器为0时,应该启用垃圾回收机制回收该内存空间,但实际上python并没有直接回收,“在不同的代码块中(注意)” 而是将对象添加到一个叫 “free_list” 的列表中作为缓存,这个机制就叫做 “free_list机制”。这是做什么呢?这就是为了在以后再创建对象时,不再重新开辟内存,而是使用 free_list 中的内存空间。我们看一段代码:
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a=9.99 >>> print(id(a)) 1699375448816 >>> del a >>> b=8.88888888 >>> print(id(b)) 1699375448816变量a被删除,该块的内存地址并没有被直接回收,而是自动添加到了 free_list 列表中,当b对象被创建时,直接使用该内存地址,无需开辟新的内存空间,这样做可以大大提高内存的使用效率。需要注意的是:python的这种缓存机制只适用于float/list/tuple/dict四种数据类型,但针对每一种数据类型它的 free_list 存储的机制和容量稍有不同,我们详细看一下。
(1)float类型,维护的free_list链表最多可缓存100个float对象,超过则释放之前的内存空间。
(2)list类型,维护的free_list数组最多可缓存80个list对象,超过则释放之前的内存空间。
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a = [1,2,3,4,5] >>> print(id(a)) 173932106760 >>> del a >>> b = ["jeeven","name","student"] >>> print(id(b)) 173932106760(3)tuple类型,维护一个free_list数组且数组容量20,元组的free_list存储的机制稍有不同,我们看一个 “栗子”。
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a=(1,2,3,4,5) >>> print(id(a)) 458961967336 >>> del a >>> b=("jeeven",2) >>> print(id(b)) 458965331144 >>> c=(1,2) >>> print(id(c)) 458965272328 >>> del c >>> d=("jeeven",2) >>> print(id(d)) 458965272328在上面的代码中,a和b并没有按照free_list的机制去存储,这是因为元组维护的free_list是按照元素个数来的,每个索引单独维护了一个数据链表,如下图所示。每个链表最多可以容纳2000个元组对象,所以说上述代码中含2个元素的c和d是存储在索引为2的数据链表中的,而a和b存储的是不同索引的链表中,所以内存地址不一致。
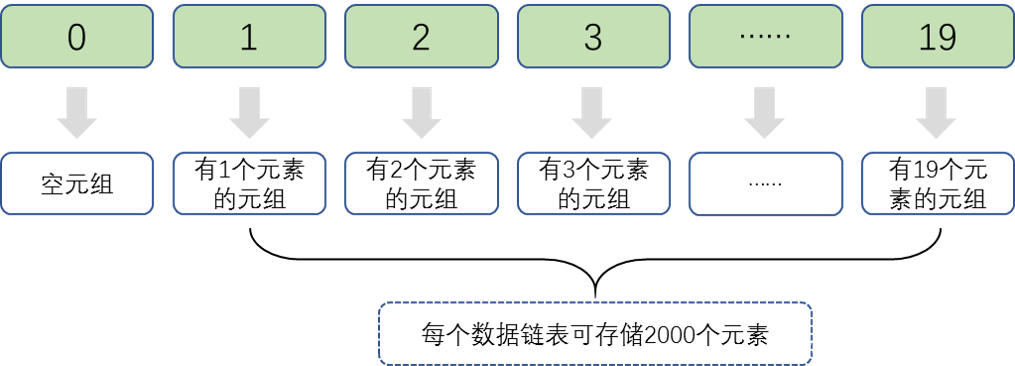
(4)dict类型,维护的free_list数组最多可缓存80个dict对象。
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a={"a":1, "b":2} >>> print(id(a)) 458961852440 >>> del a >>> b={"c":1, "d":2, "e":3} >>> print(id(b)) 458961852440好,以上就是关于 “python垃圾回收” 的所有内容,“缓存机制” 这块稍微有些混乱的,是因为不同的python版本和不同的代码块可能会给学习这部分同学内容造成困扰。所以可能当你看到这篇文章的时候,python的版本已经更新,例子运行和上面的结果不一致你也不必困扰,毕竟内存回收和内存分配,在python内部已经完全为我们自动化的去处理了所有的事情,在使用上你大可不必关心这些。而我们了解到这些原理和机制的话,希望可以对我们做开发、设计或有在使用python时更深入的理解,我想目的就达到了。下一个系列我想跟大家聊一聊python中各种数据类型在内存中的存储形式的,尽请期待。
“闻道有先后,术业有专攻。每个人都有自己精通的领域,同样也有自己的不足,有缺憾,就有可改之处,也就有进步的空间。尽力发挥自己的长处,不断完善自己的短处,每天稍有进步,日积月累终会有所大不同。” 又是新的一天,早安,我是小眼睛优粥面,欢迎大家交流分享,并指正其中的错误,万分感谢。
热门文章
- 使用pyspark读取hive数据
- 「2月9日」最高速度18.6M/S,2025年SSR/Clash/Shadowrocket/V2ray每天更新免费订阅地址分享
- 「2月15日」最高速度21.4M/S,2025年SSR/Shadowrocket/V2ray/Clash每天更新免费订阅地址分享
- 「1月5日」最高速度19.4M/S,2025年V2ray/SSR/Shadowrocket/Clash每天更新免费订阅地址分享
- 养猫的属相禁忌(养猫最忌讳属相)
- 「2月23日」最高速度20.5M/S,2025年Clash/V2ray/Shadowrocket/SSR每天更新免费订阅地址分享
- windows 平台下编译openssl 最新版本-3.0.5
- pandas读取csv文件提示字符读取失败
- 「2月21日」最高速度20.4M/S,2025年SSR/V2ray/Shadowrocket/Clash每天更新免费订阅地址分享
- 「2月16日」最高速度22.8M/S,2025年Shadowrocket/SSR/V2ray/Clash每天更新免费订阅地址分享