ELK日志我们一般都是按天存储,例如索引名为"kafkalog-2022-04-05",因为日志量所占的存储是非常大的,我们不能一直保存,而是要定期清理旧的,这里就以保留7天日志为例。
自动清理7天以前的日志可以用定时任务的方式,这样就需要加入多一个定时任务,可能不同服务记录的索引名又不一样,这样用定时任务配还是没那么方便。
ES给我们提供了一个索引的生命周期策略(lifecycle),就可以对索引指定删除时间,能很好解决这个问题。
索引生命周期分为四个阶段:HOT(热)=>WARM(温)=》COLD(冷)=>DELETE(删除)
1.配置生命周期策略(policy)
这里为ELK日志超过7天的自动删除,所以只需要用到DELETE(删除阶段)
PUT _ilm/policy/auto_delete_policy {"policy": {"phases": {"delete": {"min_age":"7d","actions": {"delete": {} } } } } }
创建一个自动删除策略(auto_delete_policy)
delete:删除阶段,7天执行删除索引动作
查看策略:GET _ilm/policy/
2.创建索引模板
索引模板可以匹配索引名称,匹配到的索引名称按这个模板创建mapping
PUT _template/elk_template {"index_patterns": ["kafka*"],"settings": {"index":{"lifecycle":{"name":"auto_delete_policy","indexing_complete":true } } } }
创建索引模板(elk_tempalte),index.lifecycle.name把上面的自动删除策略绑定到elk索引模板
创建kafka开头的索引时就会应用这个模板。
indexing_complete:true,必须设为true,跳过HOT阶段的Rollover
查看模板:GET /_template/
3.测试效果
logstash配置:
logstash接收kafka的输入,输出到es。
input { kafka { type=>"log1" topics=>"kafkalog" #在kafka这个topics提取数据 bootstrap_servers=>"127.0.0.1:9092" # kafka的地址 codec=>"json" # 在提取kafka主机的日志时,需要写成json格式 } } output {if [type] =="log1" { elasticsearch { hosts=> ["127.0.0.1:9200"] #es地址 index=>"kafkalog%{+yyyy.MM.dd}" #把日志采集到es的索引名称 # user=>"elastic" # password=>"123456" } } }
这里测试时把DELETE的日期由7天"7d"改为1分钟"1m"。
生命周期策略默认10分钟检测一次,为了方便测试,这里设为30s。
PUT /_cluster/settings {"transient": {"indices.lifecycle.poll_interval":"30s" } }
把日志写入到es后,查看日志索引的生命周期策略信息。
GET kafka*/_ilm/explain 查看kafka开头索引的生命周期策略
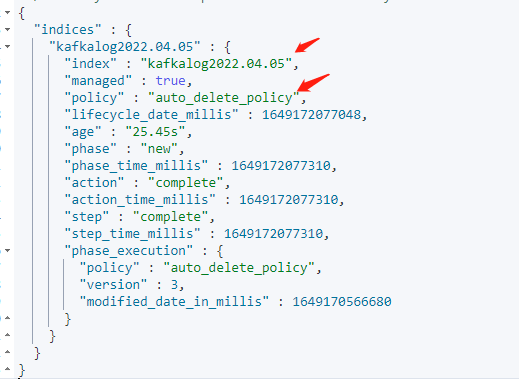
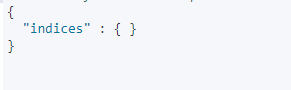
过一会再点查询,索引已经没有了,说明已经生效。
上一个:PHP重载
热门文章
- ELK日志保留7天-索引生命周期策略
- springboot整合spring retry 重试机制
- Springboot连接MySQL数据库
- 「2月3日」最高速度18.5M/S,2025年V2ray/Shadowrocket/SSR/Clash每天更新免费订阅地址分享
- 「2月1日」最高速度22.9M/S,2025年Clash/SSR/Shadowrocket/V2ray每天更新免费订阅地址分享
- 「1月19日」最高速度20.7M/S,2025年V2ray/Shadowrocket/SSR/Clash每天更新免费订阅地址分享
- vue 修饰符
- 「2月12日」最高速度18.4M/S,2025年V2ray/SSR/Clash/Shadowrocket每天更新免费订阅地址分享
- 建议穷人养的10种猫母猫和公猫混养(母猫和公猫哪个好养知乎)
- 兽用疫苗经营许可(兽用疫苗经营许可证需要什么条件)